
Big Blue

How IBM helped us find our big-company footing
The daily, slow-motion avalanche
The message servers were down. Again.
The #alerts channel lit up with dozens of error reports and outage notifications. Our Operations team scrambled to add capacity and resurrect the dead servers. It was just before 9 in the morning on the west coast. Most of the engineers hadn’t even finished their morning coffee.
It was the third outage of the week. It was Wednesday.
“There are too many users connecting. We must stop connections until we recover.” This was a message in #ops from Serguei Mourachov, co-founder of both Slack and Flickr. Unlike Stewart and Cal who led the company, Serguei kept his focus on building and maintaining the backbone of the service. He was the de facto chief engineer of what was affectionately known as our Java Industrial Complex — the unseen java servers relaying real-time traffic across the service.
Serguei was right — things would continue to get worse, perhaps taking the entire service down, if we didn’t take immediate action. Millions of people were using the product at this point, with many of them connecting every weekday around 9am eastern time or 9am pacific time. At these times of day, our servers were near their peak capacity. This was usually fine. However, when these peak times coincided with anything else that added demand, everyone’s experience on Slack would suffer.
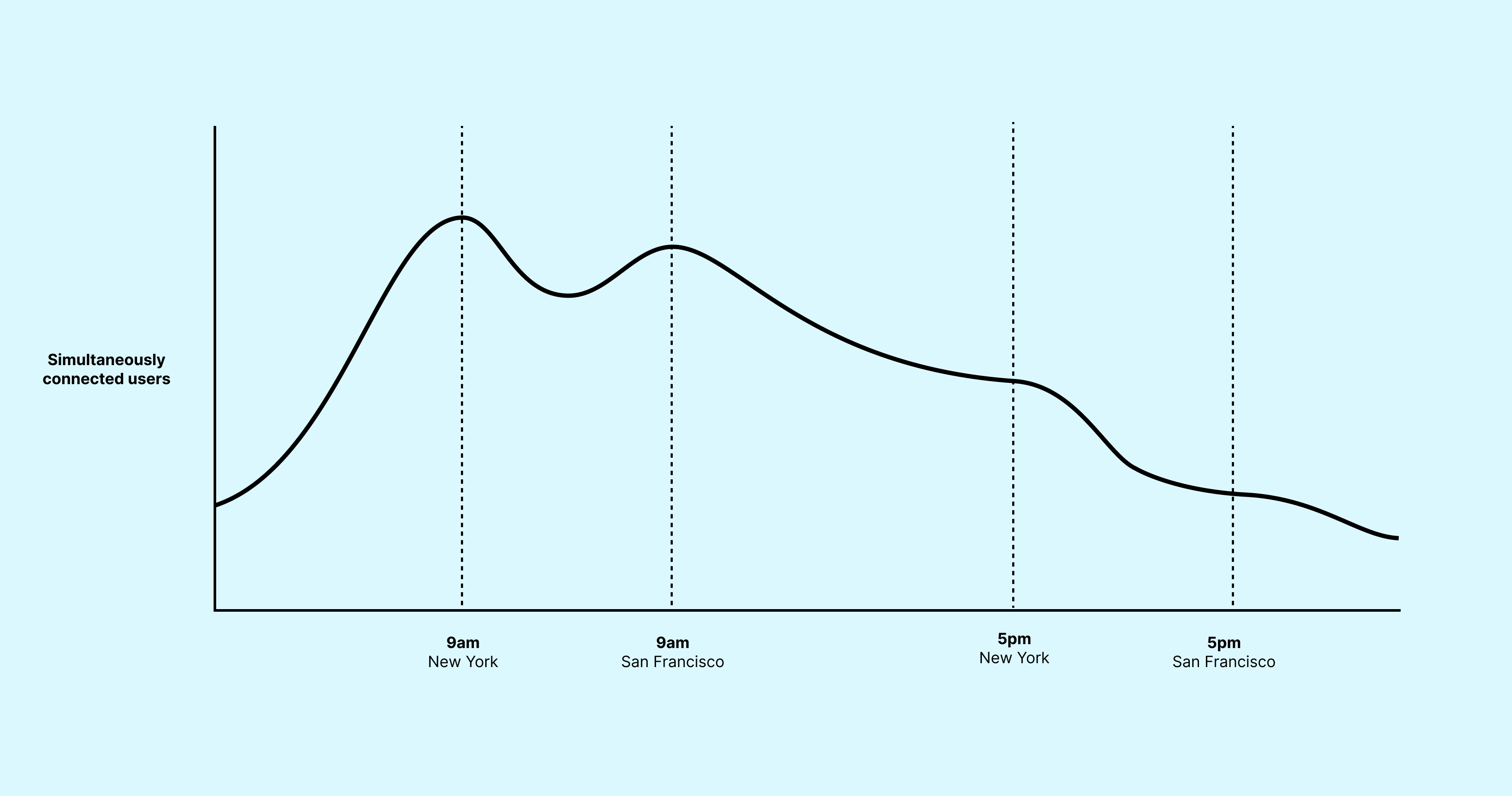
On this particular Wednesday, that added demand came from a message in a channel with 100,000 members, the largest channel on Slack at the time. Someone sent a message prefixed with the special @channel keyword, which meant that all 100,000 people in that channel would get a notification for it. That in turn meant that some large-ish percentage of those 100,000 people would follow the notification to the channel and connect to Slack, more or less simultaneously.
Connecting each person to Slack was no small task. We needed to fetch a list of each user’s channels and direct messages, figure out when the user had last read each one and retrieve new messages they hadn’t yet seen, get a fresh set of “presence” information for all the other users in that team (the 🟢 and ⚪️ online/away dots), compute a bunch of preferences and other sundry bits, package it all up in a tidy format that our apps could use, and send it along to the user’s client.
The more information there was for us to retrieve for each connecting user, the more each new connection increased load on the service. Under the pressure of too many new connections demanding too much information, Slack’s servers would overload and stop responding to requests. However, new users kept trying to connect while the ones who were trying to connect were still trying.
If our message servers went fully down during an outage, we had a new problem when they came back up — everyone would try to reconnect all at once. This is known in networked software as the “thundering herd” problem. After a period of unavailability, Slack’s message servers would be inundated with requests and couldn’t handle all the traffic, causing them to go down again. This often led to cascading failures across the service. The stampede trampled us each time we stood a server back up.
We were getting buried. The slow-motion avalanche falling on us kept building every day.
How we got here
An early key to Slack’s success was how easy it was for a team inside a big company to start using it. Our freemium model and web-based client sidestepped the traditional gatekeepers for corporate software: accounting and IT. Slack’s users didn’t need to get permission to buy or install any software to get started. Anyone could go to slack.com, set up a team, and within a few minutes start using Slack with their colleagues. This meant a lot of our early teams were small groups or departments within much bigger companies.

We experienced a constant but manageable stream of scaling issues in our first three years. We could quickly address most of these issues in standard, not-unique-to-Slack ways: adding more servers, finding slow database queries to speed up, offloading work to a cache, etc. However, as more large companies started using Slack, we started running into scaling problems that were uniquely ours, because nothing else worked quite like Slack.
The trickiest issues were the aspects of the product that had to scale geometrically. A team of 10,000 has a far higher number of possible DMs (not to mention Group DMs) than a team of 1,000. Each presence change for a person on that team is amplified across every other connected user. And so on. We could plan for this when it came to scaling our server infrastructure, but it was harder to predict how demand for server resources would interact and affect each other. Systems that were once merely complicated became complex.
We kept our eyes on a series of customers as they pushed the limits of what we could support. First it was a large US cable provider, then a large open source community. In each case, teams were using Slack with far larger groups than we had planned for, and were using it so intensively that our infrastructure was struggling to support them. We had dedicated internal channels for each of these customers, and alerts set up to fire when their activity made our infrastructure start to run hot.
Despite our attention and scaling efforts, we began experiencing repeated outages. Slack would trend on Twitter due to the number of people frantically asking if the service was down. News outlets would post sarcastic articles about reestablishing face-to-face contact with your colleagues. We would put our heads down and scramble to get the service back online.
By mid-2016, this additional server load was often coming from one customer: IBM. The nature of that pressure on our infrastructure offered us a glimpse of the mountain we needed to climb in order to scale Slack up to handle not just tens of millions of users, but a new phase in which Slack would be the communications backbone of the world's largest companies.

Big Blue comes to Tiny Aubergine
IBM’s initial journey to Slack was unremarkable: just as with every other Slack customer a group of people at IBM started using Slack in 2014 on a free team. As this team grew, forward-looking leaders within the company began taking notice. They saw that Slack was the tool that IBM’s younger engineers and designers chose to get their work done together. These teams advocated for Slack, and leadership listened: IBM decided to make Slack available to everyone on an opt-in basis.
Usage within the company quickly spread from this initial team across departments, offices, and timezones within IBM’s far-reaching global organization. That organization — one of the world’s oldest and most venerable technology companies — was home to over 350,000 people. Slack’s user base was growing rapidly during this time, and we could have easily absorbed an additional 350,000 users in “normal” teams of 10-100 people. That was the kind of linear growth we’d built the service to handle. IBM was something else.
Throughout 2015 and 2016, IBM kept growing. Not only did they have a lot of people, they had a lot of teams. And those teams used Slack an awful lot. Even without a top-down deployment or mandate, IBM had organically grown into our biggest customer. We moved their data onto dedicated database shards, allowing us to begin to isolate them from the rest of our customers and manage their scale independently. Slack had thousands of shards, but everyone knew the IBM shard by heart: 542.
We would babysit this shard, implementing IBM-specific code in various high-risk codepaths to make sure they’d stay up. Engineers got used to thinking about the IBM case for any code they were writing. Monitoring dashboards were set up just to keep track of how healthy the service was for IBM.
But we were addressing our newfound scale reactively, firefighting new issues as they arose and responding to incidents on a weekly (or sometimes daily) basis. We realized that if we were going to make a carrier-grade service to support some of the largest organizations in the world, we needed to be proactive. We couldn’t patch and provision our way out of the problem.
Figuring out how to scale
When writing software, some assumptions get encoded deeply into its architecture. As we began to grow rapidly, it became apparent that two of the assumptions we made in 2013 were wrong — we were wrong about scale, and we were wrong about how teams would be organized in a big company.
First, our assumption about the general size of teams was off by several orders of magnitude. When we started working on Slack, we thought it was going to be best for small teams. Maybe up to 100 or 150 people. This assumption was quickly disproven. Customers who started at a modest size began expanding rapidly. Five hundred people, then a thousand people, then several thousand. And now over 100,000.
Second, our assumption about how organizations would adopt Slack was wrong. Our data model initially lacked support for relationships between teams (later renamed “workspaces”). If two departments or project groups at a company started using Slack but didn’t talk to each other first, they’d end up with two Slack teams. Or in IBM’s case, hundreds of teams. We didn’t yet have the concept of Shared Channels or Enterprise Grid which would later address these needs.
Of course, this didn’t stop people at these companies from finding workarounds. They’d just join multiple teams at their company. One of those teams would typically become a kind of “home base” where everyone would join so that they could subscribe to big general audience #announcements channels.
IBM became a wonderful, gnarly problem for us to solve. Their growth and overall size placed them at the nexus of these scaling issues. We were reminded of this every weekday morning. Against the odds, IBM had bet on our fledgling startup. We needed to prove to them that we would make good on that bet.


Left: Gathering to figure out how to fix everything that was broken. Photo Julia Grace. Right: A whiteboard in our IBM war room where we worked out some of the dozens of efforts that would go into growing the service to IBM-scale. Many represented months of work to be done.
The War Room
“Get everything on the board that will make IBM’s experience less shitty,” Cal said.
This was the mandate for a group of us who gathered in a meeting room at our San Francisco headquarters one spring morning in 2017. The customer success team responsible for IBM had escalated their concerns to the top. We were at risk of losing them as a customer if we didn’t get our house in order. Though the people at IBM had been incredibly supportive and patient with us, they were understandably fed up with frequent outages and disruption to their work. We needed a plan, fast.
“Stop sending all the users to the client at startup.”
“Make presence on-demand.”
“Nudge users not to use @channel.”
“Stop logging so much stuff we never look at.”
“Don’t force a full reconnect if the client was recently connected.”
“Cap the number of people in a channel.” (Cal: “No.”)
“Send IDs only for objects and make the client ask to hydrate them.”
“Stop preloading so many messages.”
“Don’t do anything else until the first page of messages is rendered.”
The list went on. Each idea triggered more, and often led to digressions on how hard or easy something might be. The good news: we had a lot of ideas about how to make things better. The bad news: many of them represented months of work to fully implement.
Our fundamental priority was tackling the incorrect assumptions about scale that we had baked into the service and the product since 2013. The relationship between the servers and clients (the apps customers use on their phones and computers) had been built on a simple premise. When a client connects, send it everything it needs to know about a team: all the channels, people, preferences and permissions it would need to populate the app. Then send updates to those things as they changed or new messages were received. This worked really well for a long time.
But when you had hundreds of thousands of channels and people to keep track of, it didn’t. Startup time became horribly slow on big teams as the server sent a giant payload of data at connection time. The client bogged down with message volume during peak periods. Directory views (of channels, team members or files) froze up as they attempted to fetch and render long lists.
We needed to reframe the server-client relationship. Instead of loading so much data and then listening to everything coming through the firehose of message traffic, clients would request only what they needed in order to render the views on screen. We would only fetch presence for users in view, and unsubscribe from that data as soon as they weren’t visible. Channel membership would be fetched as needed instead of up front. We would rewire the clients to show placeholder UI for data that hadn’t loaded yet, rather than waiting to render a screen until the server responded. We would fetch smaller pages of message history. We would virtualize all the lists of channels and team members, loading more data in as the user scrolled down.
After a period of simplicity and small data sets, we had to make Slack more parsimonious so it could scale efficiently to whatever size of team needed it.
We prioritized the list. Some low-hanging fruit became obvious, and fixes were deployed within the day or week. Other short-term fixes were put in place to ease the most egregious issues and make downtime less likely. Medium and long term plans were spec’d out. Engineers were pulled off of feature work and assigned to these issues until they were resolved.
We rewrote a lot of the backend during this time, piece by piece. We rearchitected our databases to shard by users and channels rather than by teams so that individual large customers didn't knock us over. We deployed our highest volume services around the world, closer to our users, rather than centralized in the US.
We measured everything we could so that the whole company could rally around scaling IBM. Every performance and scale regression was recorded in a channel, and what started as a depressing mountain of work slowly paid off.
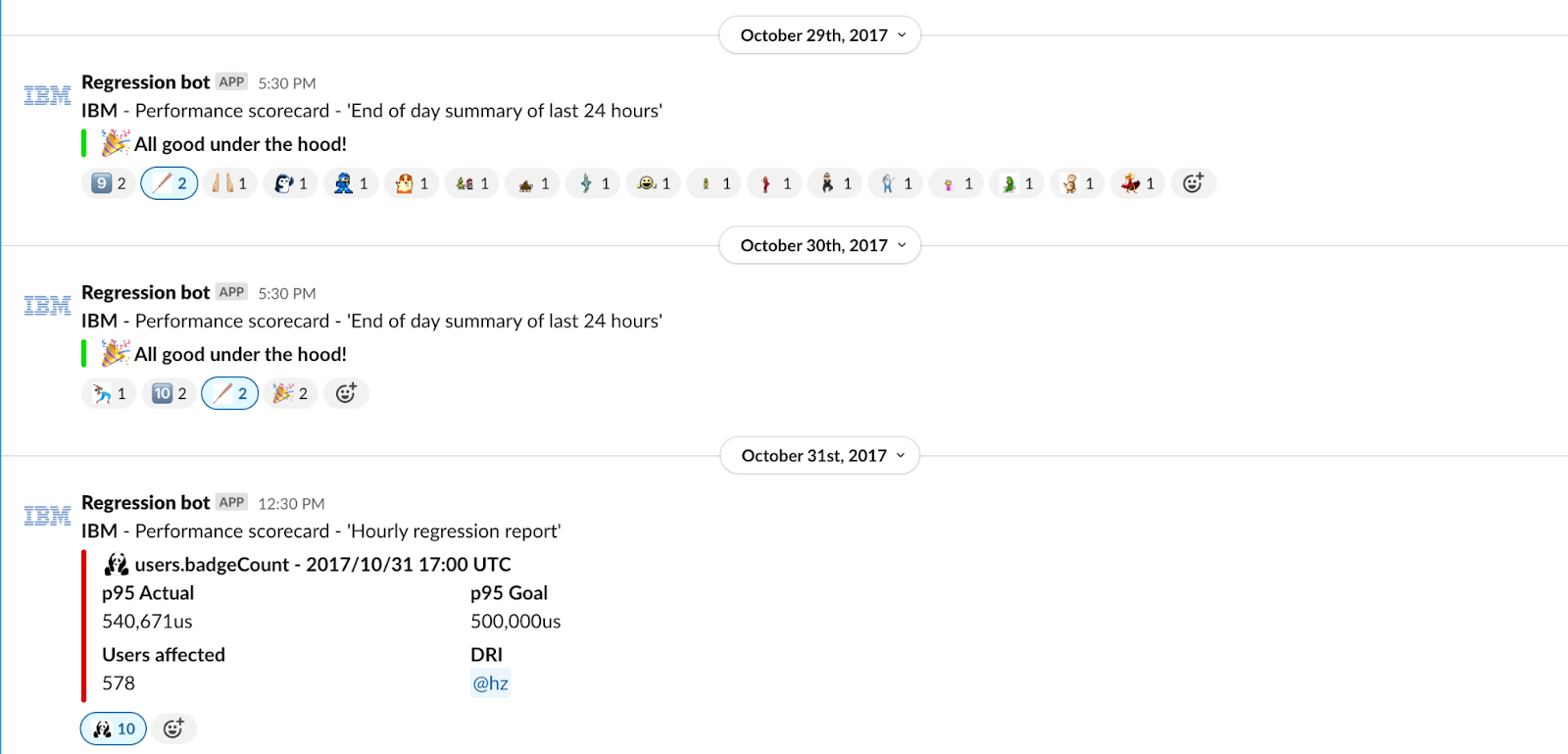
Progress was incremental and while we could see it getting better by the minute, IBM kept growing. As the service got better, they used it more. It took almost a year, but we finally got 21 unbroken days without a performance regression. We celebrated with cake. We stopped counting after we hit a streak of 64 days without incident.
IBM kept growing, but now we knew how to grow with them.
Scaling the user experience
New user experience issues also emerged with the growth of the product. Basic features that had felt solved began exhibiting new problems as the human scale of the service increased.
For example, how many people are named Matt at IBM? Or Mohamed? Certainly more than a few. Slack usernames were unique per team, and only offered simple lowercase formatting, like matt. This was normal for the types of tools Slack descended from, such as IRC. But it was unfamiliar to normal people, and impractical for large orgs where there were likely several people with the same or similar names. The first Matt to join Slack at IBM might go by matt. The next might be mattg, and so on. This quickly got cumbersome.
We introduced display names to address this issue, allowing users to set their full name including spaces and capitalization, and a preferred handle for @mentions. This solved the basic issue of many people contending for a limited namespace, and made it much easier to tell who you were talking to (and that you had the right Alice or Mia).
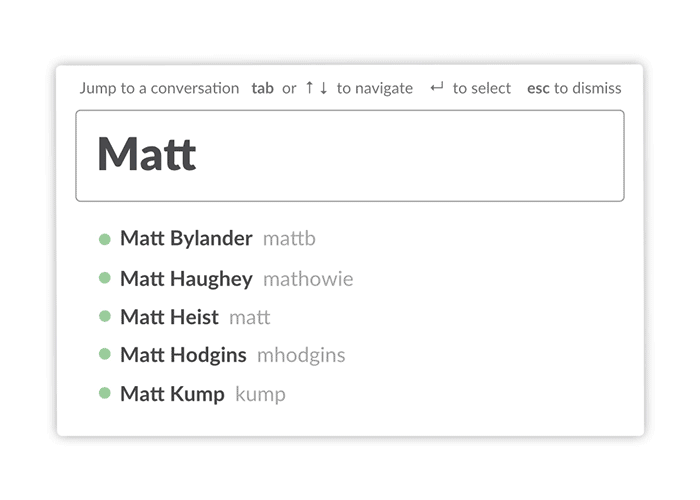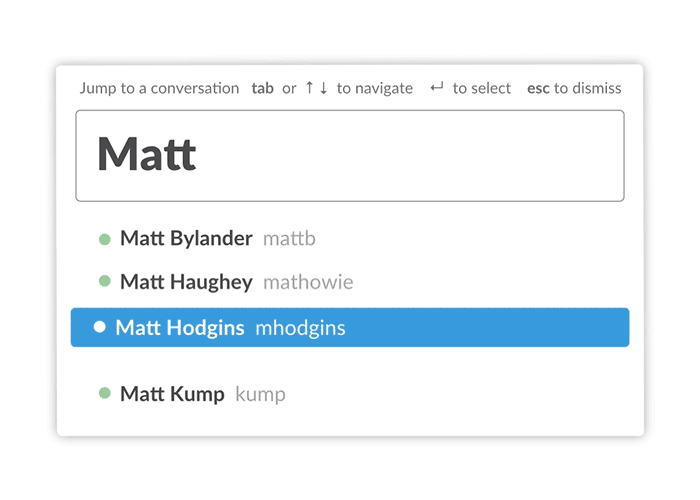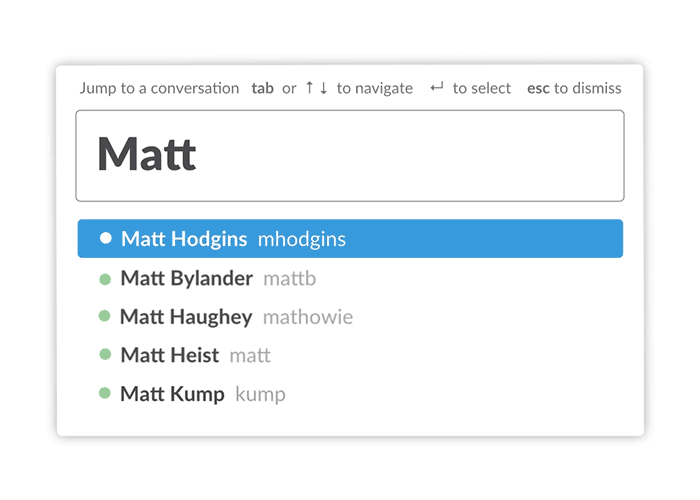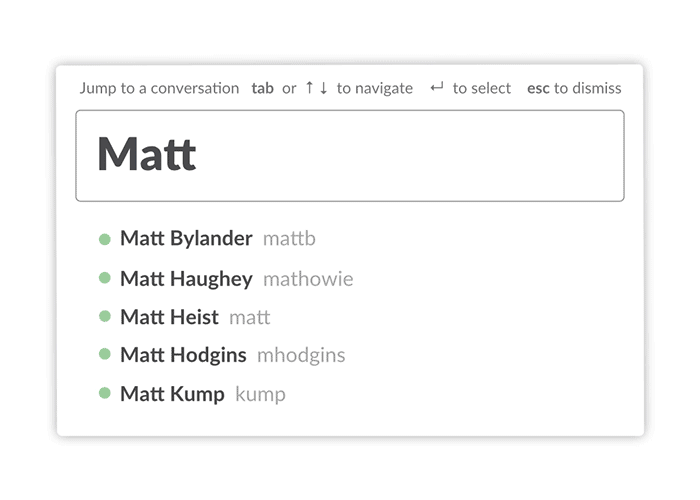
We also rebuilt the Quickswitcher to handle these cases far better. The Quickswitcher allowed keyboard users to type `cmd+k` and then the name of the channel or person they wanted. The first version of the navigation interface simply matched what you typed against channel and usernames, which worked fine on small teams. However, in larger companies it failed miserably, loading slowly and never remembering which Matt you meant.
We rebuilt it to be fast on larger datasets and introduced a frecency (frequency + recency) based sorting algorithm so that it would learn which people and channels you most commonly interact with. This allowed the interface to improve over time as you used it, so that when you typed “m” you got Matt, your colleague on the Design team you talked with several times a day, rather than Matt, the payroll guy you met once at lunch.
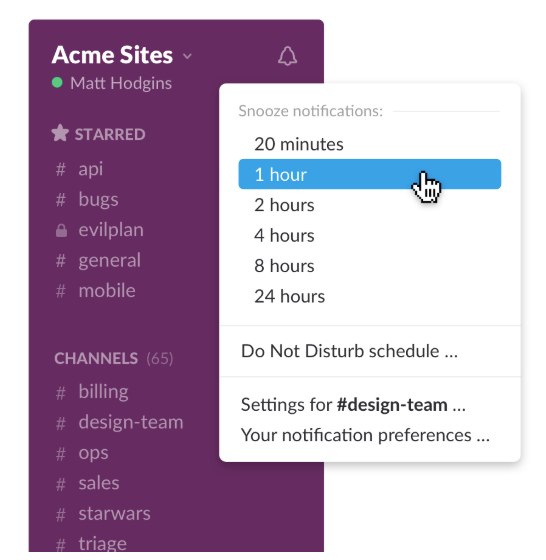
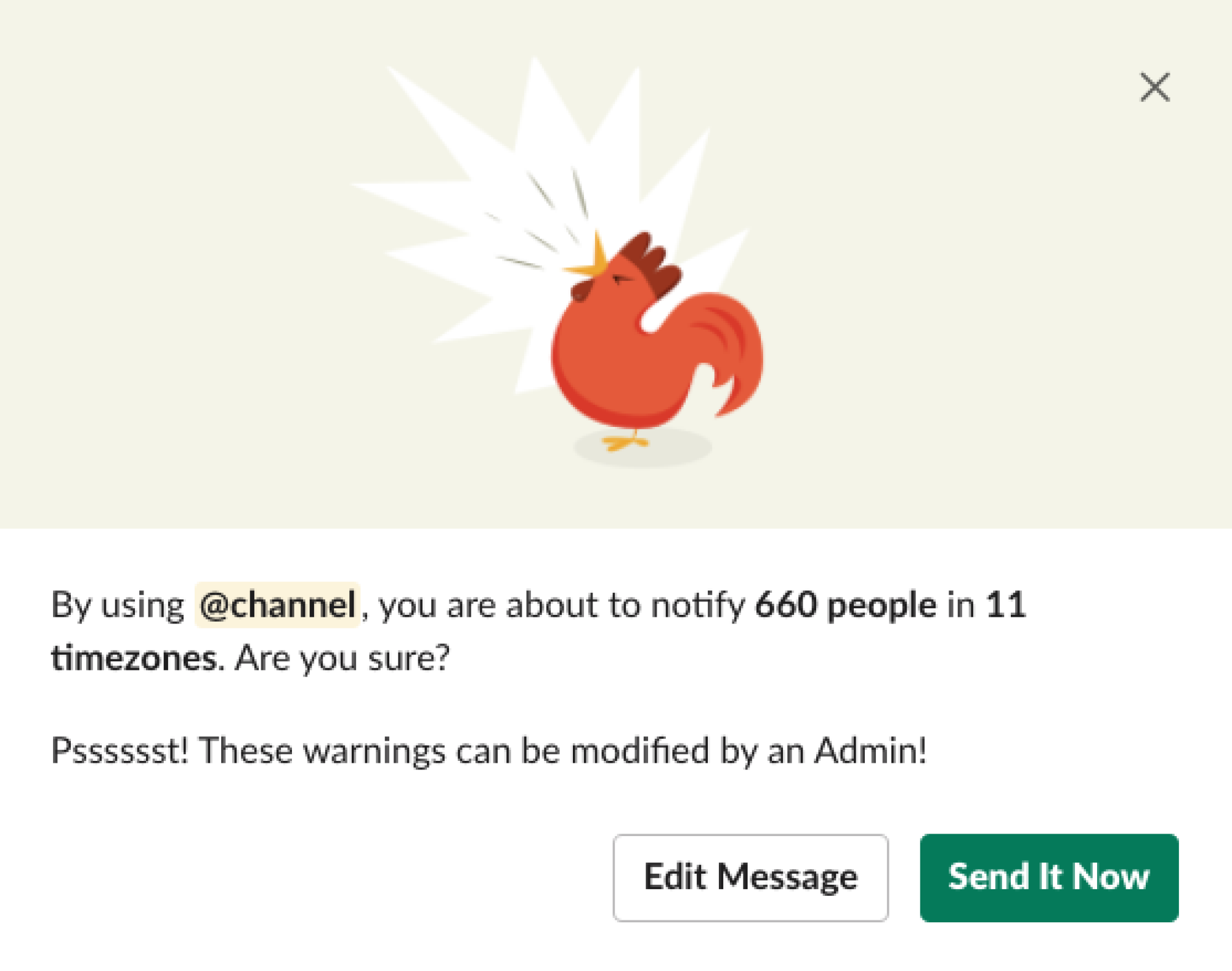
Do not Disturb options allow users to quickly quiet notifications for a predetermined amount of time or on a schedule. The “Shouty rooster” notifies a user before they broadcast a message using @channel.
Additional problems cropped up as bigger teams began using (and abusing) all the ways Slack could send a notification. Do not Disturb let people shut Slack notifications off quickly when they need to focus or switch off from work. Custom Status gave others context about what someone was doing, so they could know if it was a good time to reach out. Shouty rooster gently let senders of @channel messages know how many people (across how many timezones) they would be notifying. After all, is it really that important? (Editors: “No.”)
All of these features were built as we heard from people about the friction and interruption Slack notifications were causing them on larger teams. We were moving from a customer base of relatively small teams with cohesive expectations and social norms (such as shared working hours) to large, geographically distributed teams with more diverse needs and less coherent culture.
We strove to add options to the product that would help users make good communication choices by providing context and control regarding notifications. We needed to maintain the humanity and empathy we had imbued into the product while scaling it up to support the world’s biggest organizations. This would continue to be a major theme of our product development over the years to come.
Scaling the business
As we chipped away at reorganizing our infrastructure and feature set to support the scale of IBM and our other large customers, the other major assumption we had gotten wrong was looming. Stemming from our incorrect scale assumption (100-150 people) we had also assumed that any given company would only have one Slack team.
We were finding that many companies were adding new Slack teams every day, for each new department or project they wanted to talk about. It was getting out of control. Dozens and then hundreds of separate Slack teams at one company, unaffiliated and duplicative of one another. Users just kept adding more teams to their clients, which in turn made them slower and more demanding on our service.
We needed a product that could support the biggest organizations in the world. And it needed to allow the organizations to administer their usage of Slack in a sensible manner. IBM offered us a perfect use case: a huge company with a long history distributed across many countries around the world, with diverse working groups and complex internal operations. We figured that if we could solve this problem for them, we could solve it for anyone.
Slack started out with a business model that targeted small- to medium-sized businesses. If you bought Slack in 2014 you paid with your credit card and paid monthly or annually based on how many people used it at your company. It wasn’t long before this stopped working. As larger companies started paying for the product we cobbled together invoicing and payment methods that were more familiar to corporate accounting departments. But none of this offered a way to grapple with paying for Slack across an entire enterprise.
We set out to build what would become known as “Enterprise Grid” — a new product tier focused on rolling out Slack to large companies. We added a new data model, the organization, that could hold as many teams as a company wanted. Each was affiliated with the organization and could be managed centrally. Users were conceived of as spanning the organization. Channels were affiliated with a single team unless shared across teams. Billing for this tier was centralized in order to tame the runaway messiness of paying for additional teams as they were created. IT teams could manage users centrally across their whole organization using tools like Okta.
It was slow, messy, hard work. Unwinding assumptions as core to the data model as overall scale and team relationships was not straightforward. We updated the application architecture to plumb this new concept of an “organization” all the way from the database up to almost every view in the app.
We finally released Enterprise Grid in 2017 (more on that in a future post). It would become the central driver of our revenue and our scale as a company. After basing our business around smaller companies and a “self-serve” model, we had levelled up. Our new customers were the Fortune 500. The largest, most profitable companies in the world.
After an enormous amount of work, IBM eventually rolled out Enterprise Grid to all of their employees. After stressing our service to the breaking point, their scale became the standard we aspired to support. By meeting their needs, Slack became capable of supporting the largest global organizations in the world.
Many thanks to Bill Higgins for his efforts to champion Slack at IBM. Thank you Julia Grace for the early Infrastructure Engineering photos. Thanks to Jamie Scheinblum for his notes on this post.